You must look for real Microsoft DP-203 practice material to pass the Data Engineering on Microsoft Azure exam. Pass4itSure updated DP-203 exam dumps are the best DP-203 practice material.
Download the DP-203 exam dumps webpage https://www.pass4itsure.com/dp-203.html and you’ll see 246+ new Microsoft DP-203 practice Q&A materials to help you learn easily.

About exam DP-203: What about Data Engineering on Microsoft Azure?
For the Data Engineering on Microsoft Azure exam, you can simply call the DP-203 exam.
The DP-203 test languages are English, Chinese (Simplified), Japanese, Korean, German, French, Spanish, Portuguese (Brazil), Arabic (Saudi Arabia), Russian, Chinese (Traditional), Italian, and Indonesian (Indonesia). You’ll need to complete 40-60 exam questions in 130 minutes with a passing score of at least 700. The exam costs $165.
Passing the DP-203 exam will help candidates become Microsoft Certified: Azure Data Engineer Associates.
What are the effective DP-203 exam learning resources?
- Azure for the Data Engineer
- Store data in Azure
- Data integration at scale with Azure Data Factory or Azure Synapse Pipeline
- Realize Integrated Analytical Solutions with Azure Synapse Analytics
- Work with Data Warehouses using Azure Synapse Analytics
- Perform data engineering with Azure Synapse Apache Spark Pools
- Work with Hybrid Transactional and Analytical Processing Solutions using Azure Synapse Analytics
- Data engineering with Azure Databricks
- Large-Scale Data Processing with Azure Data Lake Storage Gen2
- Implement a Data Streaming Solution with Azure Streaming Analytics
How to efficiently prepare for the Data Engineering on Microsoft Azure exam?
- Familiarize yourself with the basics of the DP-203 exam
In order to be better prepared, the basics of the Microsoft DP-203 exam will be necessary.
- Find the real Microsoft DP-203 practice material
The Pass4itSure DP-203 exam dumps are a great choice for you, containing real and up-to-date exam practice materials to help you pass.
- Practice regularly
With the DP-203 exam practice, you will learn about your weaknesses and strengths. Thus successfully cracking the exam.
Practice DP-203 Free Dumps Questions and Answers
QUESTION 1
You are developing a solution that will stream to Azure Stream Analytics. The solution will have both streaming data and reference data. Which input type should you use for the reference data?
A. Azure Cosmos DB
B. Azure Blob storage
C. Azure IoT Hub
D. Azure Event Hubs
Correct Answer: B
Stream Analytics supports Azure Blob storage and Azure SQL Database as the storage layer for Reference Data.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-use-reference-data
QUESTION 2
DRAG DROP
You need to create a partitioned table in an Azure Synapse Analytics dedicated SQL pool. How should you complete the Transact-SQL statement? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

Correct Answer:

Box 1: DISTRIBUTION
Table distribution options include DISTRIBUTION = HASH ( distribution_column_name ), assigns each row to one distribution by hashing the value stored in distribution_column_name.
Box 2: PARTITION
Table partition options. Syntax:
PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] FOR VALUES ( [ boundary_value [,…n] ] ))
Reference:
https://docs.microsoft.com/en-us/sql/t-sql/statements/create-table-azure-sql-data-warehouse?
QUESTION 3
You have an Azure subscription linked to an Azure Active Directory (Azure AD) tenant that contains a service principal named ServicePrincipal1. The subscription contains an Azure Data Lake Storage account named adls1. Adls1 contains a folder named Folder2 that has a URI of https://adls1.dfs.core.windows.net/container1/Folder1/Folder2/.
ServicePrincipal1 has the access control list (ACL) permissions shown in the following table.

You need to ensure that ServicePrincipal1 can perform the following actions:
1. Traverse child items that are created in Folder2.
2. Read files that are created in Folder2.
The solution must use the principle of least privilege. Which two permissions should you grant to ServicePrincipal1 for Folder2? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Access – Read
B. Access – Write
C. Access – Execute
D. Default-Read
E. Default – Write
F. Default – Execute
Correct Answer: DF
Execute (X) permission is required to traverse the child items of a folder. There are two kinds of access control lists (ACLs), Access ACLs and Default ACLs. Access ACLs: These control access to an object. Files and folders both have Access ACLs.
Default ACLs: A “template” of ACLs associated with a folder that determine the Access ACLs for any child items that are created under that folder. Files do not have Default ACLs.
Reference:
https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-access-control
QUESTION 4
HOTSPOT
You are designing an enterprise data warehouse in Azure Synapse Analytics that will store website traffic analytics in a star schema. You plan to have a fact table for website visits. The table will be approximately 5 GB. You need to recommend
which distribution type and index type to use for the table. The solution must provide the fastest query performance. What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
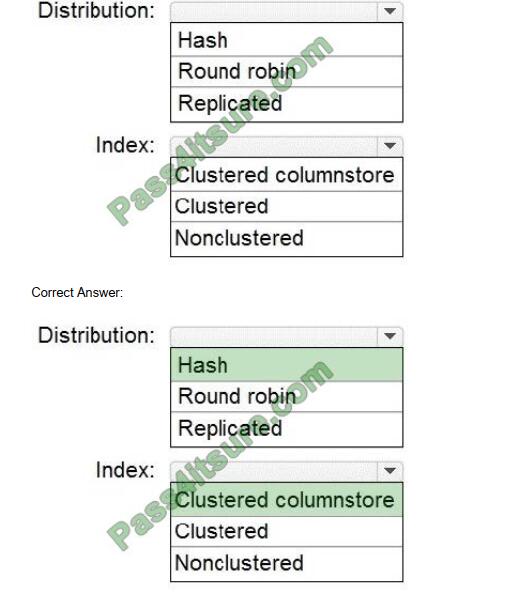
Box 1: Hash
Consider using a hash-distributed table when:
The table size on disk is more than 2 GB.
The table has frequent insert, update, and delete operations.
Box 2: Clustered columnstore
Clustered columnstore tables offer both the highest level of data compression and the best overall query performance.
QUESTION 5
You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1. You need to determine the size of the transaction log file for each distribution of DW1. What should you do?
A. On DW1, execute a query against the sys.database_files dynamic management view.
B. From Azure Monitor in the Azure portal, execute a query against the logs of DW1.
C. Execute a query against the logs of DW1 by using the Get-AzOperationalInsightsSearchResult PowerShell cmdlet.
D. On the master database, execute a query against the sys.dm_pdw_nodes_os_performance_counters dynamic management view.
Correct Answer: A
For information about the current log file size, its maximum size, and the autogrow option for the file, you can also use the size, max_size, and growth columns for that log file in sys.database_files.
QUESTION 6
You have an Azure Data Factory that contains 10 pipelines. You need to label each pipeline with its main purpose of either ingest, transform, or load. The labels must be available for grouping and filtering when using the monitoring experience in Data Factory.
What should you add to each pipeline?
A. a resource tag
B. a correlation ID
C. a run group ID
D. an annotation
Correct Answer: D
Annotations are additional, informative tags that you can add to specific factory resources: pipelines, datasets, linked services, and triggers. By adding annotations, you can easily filter and search for specific factory resources.
Reference: https://www.cathrinewilhelmsen.net/annotations-user-properties-azure-data-factory/
QUESTION 7
DRAG DROP
You are responsible for providing access to an Azure Data Lake Storage Gen2 account. Your user account has contributor access to the storage account, and you have the application ID and access key. You plan to use PolyBase to load data into an enterprise data warehouse in Azure Synapse Analytics. You need to configure PolyBase to connect the data warehouse to storage account.
Which three components should you create in sequence? To answer, move the appropriate components from the list of components to the answer area and arrange them in the correct order.
Select and Place:

Step 1: a database scoped credential
To access your Data Lake Storage account, you will need to create a Database Master Key to encrypt your credential secret used in the next step. You then create a database scoped credential.
Step 2: an external data source Create the external data source. Use the CREATE EXTERNAL DATA SOURCE
command to store the location of the data. Provide the credential created in the previous step.
Step 3: an external file format Configure data format: To import the data from Data Lake Storage, you need to specify the External File Format. This object defines how the files are written in Data Lake Storage.
QUESTION 8
You have an enterprise data warehouse in Azure Synapse Analytics. Using PolyBase, you create an external table named [Ext].[Items] to query Parquet files stored in Azure Data Lake Storage Gen2 without importing the data to the data warehouse.
The external table has three columns. You discover that the Parquet files have a fourth column named ItemID. Which command should you run to add the ItemID column to the external table?

A. Option A
B. Option B
C. Option C
D. Option D
Correct Answer: C
Incorrect Answers:
A, D: Only these Data Definition Language (DDL) statements are allowed on external tables:
1. CREATE TABLE and DROP TABLE
2. CREATE STATISTICS and DROP STATISTICS
3. CREATE VIEW and DROP VIEW
Reference: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-external-table-transact-sql
QUESTION 9
You have an Azure Synapse Analytics dedicated SQL pool. You run PDW_SHOWSPACEUSED(dbo,FactInternetSales\’); and get the results shown in the following table.
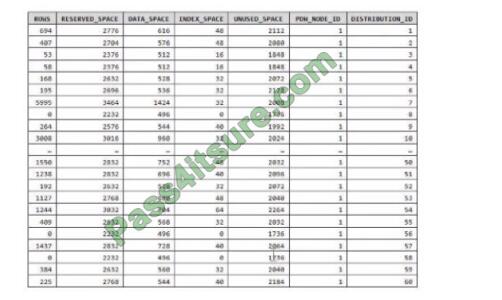
Which statement accurately describes the dbo,FactInternetSales table?
A. The table contains less than 1,000 rows.
B. All distribution contain data.
C. The table is skewed.
D. The table uses round-robin distribution.
Correct Answer: C
Data skew means the data is not distributed evenly across the distributions.
QUESTION 10
A company has a real-time data analysis solution that is hosted on Microsoft Azure. The solution uses Azure Event Hub to ingest data and an Azure Stream Analytics cloud job to analyze the data. The cloud job is configured to use 120 Streaming Units (SU).
You need to optimize performance for the Azure Stream Analytics job. Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
A. Implement event ordering.
B. Implement Azure Stream Analytics user-defined functions (UDF).
C. Implement query parallelization by partitioning the data output.
D. Scale the SU count for the job up.
E. Scale the SU count for the job down.
F. Implement query parallelization by partitioning the data input.
Correct Answer: DF
D: Scale out the query by allowing the system to process each input partition separately.
F: A Stream Analytics job definition includes inputs, a query, and output. Inputs are where the job reads the data stream from.
Reference: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-parallelization
QUESTION 11
DRAG DROP
You need to build a solution to ensure that users can query specific files in an Azure Data Lake Storage Gen2 account from an Azure Synapse Analytics serverless SQL pool. Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive credit for any of the correct orders you select.
Select and Place:
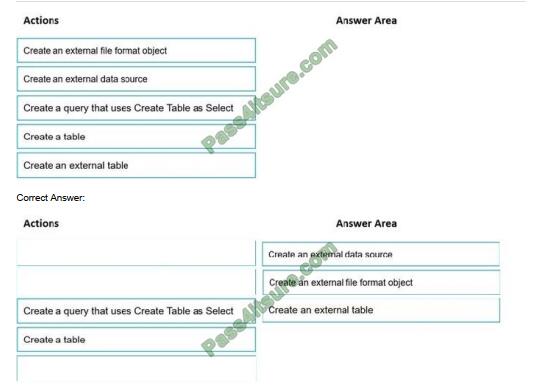
Step 1: Create an external data source
You can create external tables in Synapse SQL pools via the following steps:
CREATE EXTERNAL DATA SOURCE to reference external Azure storage and specify the credential that should be used to access the storage. CREATE EXTERNAL FILE FORMAT to describe the format of CSV or Parquet files. CREATE EXTERNAL TABLE on top of the files placed on the data source with the same file format.
Step 2: Create an external file format object
Creating an external file format is a prerequisite for creating an external table.
Step 3: Create an external table
QUESTION 12
You have an Azure Stream Analytics query. The query returns a result set that contains 10,000 distinct values for a column named cluster. You monitor the Stream Analytics job and discover high latency. You need to reduce the latency.
Which two actions should you perform? Each correct answer presents a complete solution. NOTE: Each correct selection is worth one point.
A. Add a pass-through query.
B. Add a temporal analytic function.
C. Scale out the query by using PARTITION BY.
D. Convert the query to a reference query.
E. Increase the number of streaming units.
Correct Answer: CE
C: Scaling a Stream Analytics job takes advantage of partitions in the input or output.
Partitioning lets you divide data into subsets based on a partition key. A process that consumes the data (such as a Streaming Analytics job) can consume and write different partitions in parallel, which increases throughput.
E: Streaming Units (SUs) represent the computing resources that are allocated to execute a Stream Analytics job. The higher the number of SUs, the more CPU and memory resources are allocated for your job. This capacity lets you focus on the query logic and abstracts the need to manage the hardware to run your Stream Analytics job in a timely manner.
References: https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-parallelization
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-streaming-unitconsumption
QUESTION 13
You are designing an Azure Stream Analytics solution that will analyze Twitter data. You need to count the tweets in each 10-second window. The solution must ensure that each tweet is counted only
once. Solution: You use a tumbling window, and you set the window size to 10 seconds. Does this meet the goal?
A. Yes
B. No
Correct Answer: A
Tumbling windows are a series of fixed-sized, non-overlapping and contiguous time intervals. The following diagram illustrates a stream with a series of events and how they are mapped into 10-second tumbling windows.
For more information on the answers to questions about the DP-203 exam, here.